地球,太阳每时每刻都在变,但“太阳从地球的东方升起”不会变;汉字会变,但汉字字形的内在规律不会变,“和码汉字字形技术”是汉字字形内在规律的科学揭示。
《和码》是“和码汉字字形技术”的简称,其核心内容是“汉字字形编码方案”。要说明“和码是最好最终的汉字形码”并不难,只要从汉字字符集的限定性,字形与字结构的限定性,汉字形码方案诸要素的可选择性与限定性,进行分析就可以得出结论。
汉字形码方案的研究对象是:汉字与汉字集,汉字的组成笔画与字根,以及字形结构。形码方案的5个要素是:①编码符号,②码个数,③笔画与字根的分区分位方法,④单字的取码方法,⑤码长。以下就这几个方面逐个地进行分析论证。
我们使用的汉字库,不论是国家标准GB2312-80的6763个汉字,还是GB18030-2000 的2万7千个汉字,还是国际标准Unicode的20902个汉字,以及更大的汉字库中的汉字,都是前人创造出来的,以固定形式存在的。
未来是否有新的图形汉字创造出来呢?如果谁造了个新的图形汉字,又希望别人使用,这个新字就必需能在自己的和别人的电脑上显示出来,这个新字就需要在获得批准之后,加入到国家标准字库,或国际标准字库中。
在现有的2万多个汉字的基础上,再增加新的图形汉字,除要得到人们的认可外,还要把新汉字加入到标准字库中,这会是个复杂又漫长的过程,这就使再造新汉字尝试,没有多大的意义,也难于成功。
因此汉字是已经存在的,图形固定的,数目有限的符号集。
汉字集是固定的,那么组成这些字的字形要素,也就是确定的。这些要素是基本笔画,字根,与字形结构。汉字的基本笔画是横竖撇点捺与对应的折笔画,字根大致为600多个,汉字结构是独体字、二块字、三块字等,或是上下结构,左右结构、内外结构等。
汉字形码方案的设计,就是把汉字集中单字的组成笔画与字根,按照易学易记的要求,进行合理的分区分位排布成一个字根表,根据单字的结构特点,按照易学易用的要求,制定一个单字取码方案。字根表与单字取码方法就是汉字形码方案的全部内容。
对于现存的固定的汉字集,确定的字形要素,在易学易记易用的要求下,汉字形码的编码方案(字根表与单字取码方法)不会是无限多的,这是汉字形码研究有终点的原因。
大家知道,中国围棋的下法是无限多的,因为双方比的是复杂难懂的排布方法,但如果围棋对弈的双方,比的是用最简单最易懂的方式排布棋子,那就只有一种排布方式,即黑子做两个棋眼占半边,白子做两个棋眼摆在另半边。
道理相似,如果汉字编码的目是难学难记,那几千个单字的排布方法,比围棋还要复杂得多,输入汉字就比下围棋还要难。所幸的是汉字编码追求的是易学易记易用,这样合格的汉字编码就有个数了。
在易学易记易用的要求下,汉字字形的编码方案(字根表与单字取码方法)也就存在几类几种,最具代表性的有以下几类。
①单笔画类:如手机上的各种笔画输入法;
②双笔画类:如二笔输入法;
③字根类:五笔字型,表形码,郑码,和码等。
更值得庆幸的是,汉字形码还存在一个最好最终的方案。
编码所采用的符号有以下两种。
①英文字母符号。如:五笔字型,表形码,郑码等。
用字母符号编码的输入法,能在电脑大键盘上使用,但不能直接有效地应用于手机与数字小键盘。
字母与数字没有易记易用的对应关系,如字母‘G’的顺序号是7,‘J’的顺序号是10,谁能直接读出呢?因此字母不能按照其顺序号输入,只能把26个英文字母印在10数字键上,2~3个字母共用一个数字键。因此26个字母编码的输入法,在手机上就变成了10个码的输入法,重码率就大幅度上升(20倍)以上,基本上失去了使用的价值。
另外,有的形码输入法,把汉字字根与英文字母,通过形相似(称为“形托”)联系在一起。 汉字字根与英文字母是没有任何关系的,把汉字的‘口’看成是‘O’,‘阝’看成是‘P’,那么‘王、木、人、氵’又象那个英文字母呢?在两个本不相关的事物中找关系,只能是主观,牵强和难于接受。
②阿拉伯数字符号。如:和码输入法,T9数字输入法等。
数字代表的是顺序,而不是形,如12345,一二三四五,与ⅠⅡⅢⅣⅤ表示的是相同的意思(顺序),而不是符号形状。
和码采用25个数字符号,25个数字码按顺序排布上电脑的大键盘上,通过25个位置键输入。和码中,电脑的字母大键盘,被看成是(也用作为)数字大键盘。
在手机与数字小键盘上,通过1、2、3、4、5五个键的两两组合输入和码的25个数字码。
 |
和 |  |
数字符号能在字母大键盘,数字小键盘与手机键盘上方便地输入,因此为了使汉字形码在不同的输入设备上统一通用,编码符号就应该采用数字符号,数字符号是最好最终的选择。
和码采用25个数字码对汉字编码,实现了同一个字根表,同一种单字取码方法,在电脑字母大键盘,数字小键盘与手机上的统一通用,并具有同样低的重码率。这是以往的汉字形码输入法没有做到的。
各种汉字形码编码方案的码个数有所不同,如5,6,9,10,25,26,28,30,36个等等,那么,多少个码最合适呢?
首先通过以下3组数字,了解一下汉字集的大小,常用汉字的多少及其在文字资料中的覆盖率。
1、国家标准GB2312-80收集了6763个简体汉字,国家标准GB18030-2000收集有2万7千个中日韩(包括大陆,台湾,香港)的汉字。
2、著名计算语言学家冯志伟教授的统计数据:《信息时代汉字的标准化和共通化》
7000通用汉字覆盖率和不足率
| 汉字数 | 增加字数 | 覆盖率 | 不足率 |
| 1000 | 90% | 10% | |
| 2400 | 1400 | 99% | 1% |
| 3800 | 1400 | 99.9% | 0.1% |
| 5200 | 1400 | 99.99% | 0.01% |
| 6600 | 1400 | 99.999% | 0.001% |
从中可以看出,1000个汉字的覆盖率为90%,以后每增加1400字,覆盖率百分比的最后一个9字之后便增加一个9字。覆盖率达到99.999%的6600个汉字,就构成了现代通用汉字的主体,覆盖率达到99.9%的3800个汉字,就包含了全部现代常用汉字。
3、据统计,红楼梦书只用了4200个单字,毛泽东选集一至四卷也只用了2981个字。
从上面的数据可以看到,汉字很多,但常用汉字并不多。常用汉字可以粗略地定为3800(或5200)个,因为其覆盖率达到了99.9%(或99.99%),因此汉字输入法只要能方便快速地输入这3800(或5200)个常用汉字就行了。
对于3800(或5200)以外的数目巨大的非常用汉字集,因其覆盖率只有0.1%(或0.01%),即通常情况下输入1千(或1万)个汉字,才会碰到非常用汉字集中的一个汉字,因此输入法不必追求对这些非常用汉字的输入速度,只要能输入就行(即允许重码)。
因此“多少个码最合适”的问题,就可以表述为:为了方便快速地输入3800(或5200)个常用汉字,多少个码最合适呢?方便快速,就是取码次数少,重码少。
①、10(或少于10)个码不合适
如用10个码编码,每个字4码,共有10,000(一万)个码位,分配给这3800(或5200)个汉字,一字一码(无重码),还有很多码多余(空着)。这看起来很容易,但因汉字结构的特殊性,实际编起来,无论你怎样在10个数上排布字根,无论你想出什么规则对汉字进行编码,得到的结果都是重码太多。即使每个汉字用5个数字编码(码位有十万个),或每个汉字用6个数字编码(码位为百万个),3800(或5200)个汉字仍有很多重码。
10个输入码的汉字形码,无论字根表与取码方法如何,都有重码太多,取码次数太多(6个)的严重缺陷,都不能实现对这些常用汉字的方便快速地输入。 T9笔画输入法,取码次数多,重码多,其它10(或少于10)个码的输入法,也都有相同的缺点。
②、和码的统计数据(范围是GB2312-80的6763个汉字)
和码软件在四个码的输入过程中,任何单字最多只有一次机会被选在待上屏位置,最常用的字,最早被选上。
输入第一个码,有25个字可被选在待上屏位置;
输入第二个码后,新增617个字(不包括第一码的25个字);
输入第三个码后,新增4434个字可被选在待上屏位置(不包括第一、二码的25+617个字);
输入第四个码后,新增1544个字可被选在待上屏位置(不包括第一、二、三码的25+617+4434个字)。
在三个码的范围内,和码能将25+617+4434=5076常用汉字先后放在待上屏位置,即能实现对3800(或5200)个常用汉字的方便快速输入。虽然和码三个码内输入的5076个常用汉字,不可能就是3800(或5200)所含的常用汉字,但肯定包括了其中的绝大多数,且越常用的字,越可能被包括。和码三码内,没有输入的少数常用汉字,在输入第四个码时,极有可能被选在待上屏位置。
③、25个码与30个码的比较
一般地,增加码的个数,能大幅增加码位的容量,如:
25个码,每个汉字三个码,编码的容量:25+25*26+25*25*26=16275。
30个码,每个汉字三个码,编码的容量:30+30*31+30*30*31=28860。增幅77.33%。
但30个码与25个码相比,对于提高3800(或5200)个常用汉字的输入速度,却效果甚微。
以下是在理想的编码情况下,25个码与30个码对3800(或5200)个常用汉字进行编码,再输入这些字的最少击键次数的比较:
理想的情况是:(理想情况下的输入速度,是汉字输入的极度速度)
1、所有的汉字都没有重码;
2、一码字与二码字的所有码位上,都能排上汉字,且一码字,二码字,三码字都不互相重叠。
用25个码编码后,输入这些汉字的最少击键次数:
一码字:25个,击键次数25次;
二码字:25*26=650个,击键次数1300次;
三码字:3800(或5200)-650-25=3125(或4525)个,击键次数为3125(4525)*3=9375(或13575)次;
3800(或5200)个单字的最少击键数为:9375(或13575)+1300+25=10700(或14900)。
用30个码编码后,输入这些汉字的最少击键次数:
一码字:30个,击键次数30次;
二码字:30*31=930个,击键次数为930*2=1860次;
三码字:3800(或5200)-930-30=2840(或4240)个,击键次数为2840(或4240)*3=8520(或12720);
3800(或5200)个单字的最少击键数为:8520(或12720)+1860+30=10410(或14610)。
在理想的编码条件下,30个码与25个码相比,输入3800(或5200)个汉字的击键次数少:10700(或14900)- 10410(或14610)=290(或290)次,即少2.7%(或1.95%)的击键数,输入速度增幅也是这个比例。这说明25个码后,再增加码个数,对于提高的输入速度,作用很小。这说明对于3800(或5200)个常用汉字,输入法的速度有极限。
25个码到30个码,码位的空间由16275增加到28860,增幅为77.33%,但输入速度的增幅仅有2.7%(或1.95%),重要原因是汉字常用字是有限的3800(或5200)个。
有人会说,理想的编码统计结果与实际编码有很大的出入,我们下面就来分析实际的编码情况。
实际的编码情况会是:
1、有些汉字的编码完全一样,有重码;
2、二码字的码位上,有些排不上汉字,是空位。
这些实际情况对于25个码,与30个码的方案都会出现。实际上和码在二码位上排了619个字,只有31个空位,是很接近理想的情况了。因此不论30个码的方案实际编码情况与理想值的差距如何,即使是理想值,其输入速度与25个码的和码相比,都不会有明显的增加(少于3%)。这也说明和码的输入速度,也接近汉字输入的极限速度。
词组在日常汉字输入中应用非常普遍,对汉字输入速度有很大的影响。 汉字词组与单字一样,也有常用词组与覆盖率,估计认为6万(或8万)常用词组的覆盖率能达到99.9%(或99.99%)。
由于词组的输入大多数都要用到第四个码,因此25个码的词组的容量为25*25*25*26=40万余条,30个码的词组容量为30*30*30*31=81万余条。这些数字都远大于常用词组的数量。
与上面单字的分析一样,由25个码到30个码,词组的码位容量由40万条增加到81万条,但对常用词组的输入速度不会有明显的增幅,重要原因是常用词组的数目只有6万,25个码的和码已经能方便快速地输入这些词组了。
然而30个码(或更多个码)却有以下缺点:
①与和码的5×5区位排布相比,6×5,5×6,6×6等区位排布都复杂难记些;
②在现有的通用大键盘上,要使用非英文字母键做输入键,给输入带来不便。
从上面的分析可以看出,25个码的和码之后,再增加码的个数对提高汉字的输入速度影响很小。因此对现有的汉字集与常用汉字编码,25个码是最好的码个数。只要汉字集不变,常用汉字不大幅增多或减少,25个码最好也就不会变。
形码的易学易记性,主要是看字根表的分区分位方法。
1、字根表的分区,一般是以汉字基本笔画的分类方法为依据,以往形码都把汉字的基本笔画分为“横竖撇点折”五类,其中“折”类包括横折,竖折,撇折。因此把字根表分为“横竖撇点折”5个区与5个位,但汉字在这5区5位中的分布极不均匀,以国标GB2312字符集的6763个字为例,理想的排布是每区1352.6个字各占总数的20%,但实际在横区中汉字有1962个占29.0%,在折区的汉字为732个占10.8%。再加上“横竖撇点折”的分位规则,就造成了在“横与横,横与竖,竖与折,点与点”等码位上集中了太多的单字,而在“横与折,横与点,竖与撇,竖与点,折与横”等码位上,就只有很少的单字,这样严重的不均衡,使得重码很多,做出来的汉字形码没有实用的价值,为了克服这个缺点,各形码输入法都对字根做跨区跨位调整,调整后的字根表就没有了一致的有规律的顺序,字根表就难学难记了。
和码将汉字的基本笔画归纳为“横竖撇点”四类,把横与横折放在一起,竖与竖折放在一起,撇与撇折放在一起。考虑到横与横折起笔的字根与汉字最多,在对汉字分区时,就把横分为两个区,即把与其它笔画相交的横起笔的字根(如:扌土艹大木等)单独作为一区(第三区)。
和码把字根表分为“横竖十撇捺”五个区,每个区又把笔画与字根,按其对字形与字义的限定性大小(由简到繁)的顺序分为5个位。
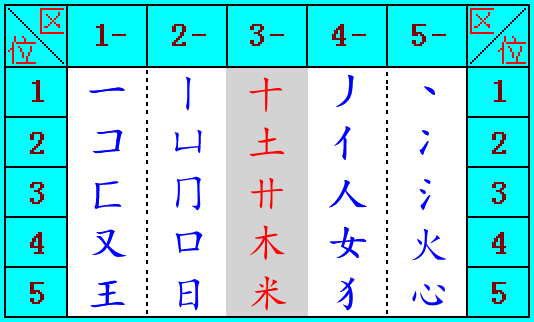
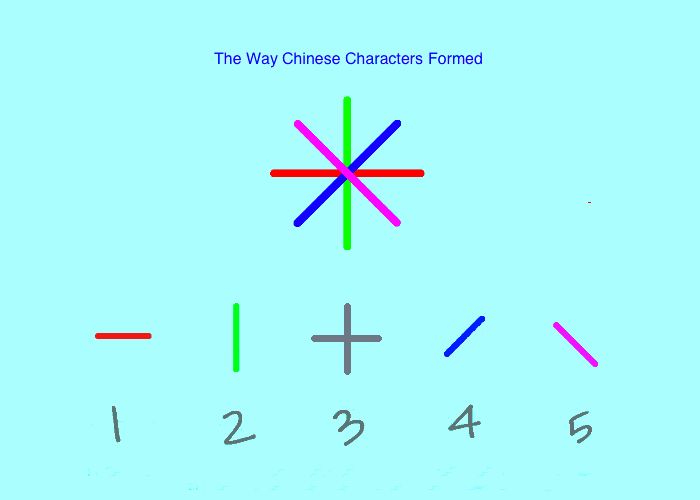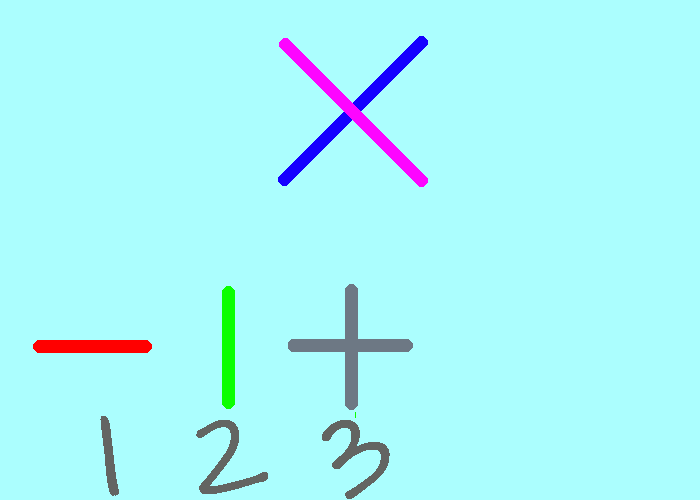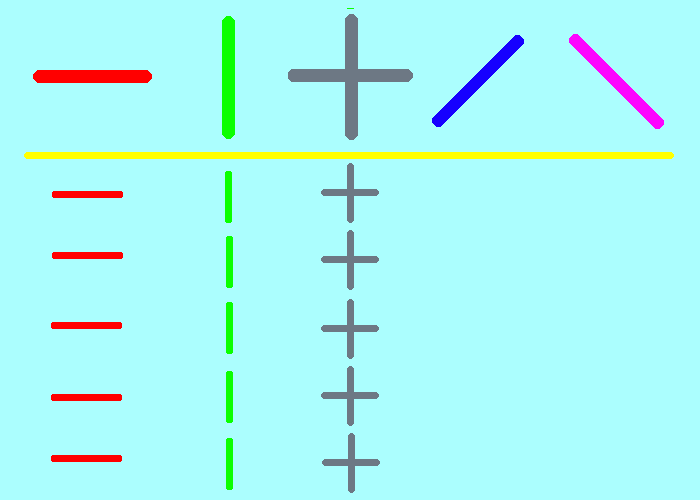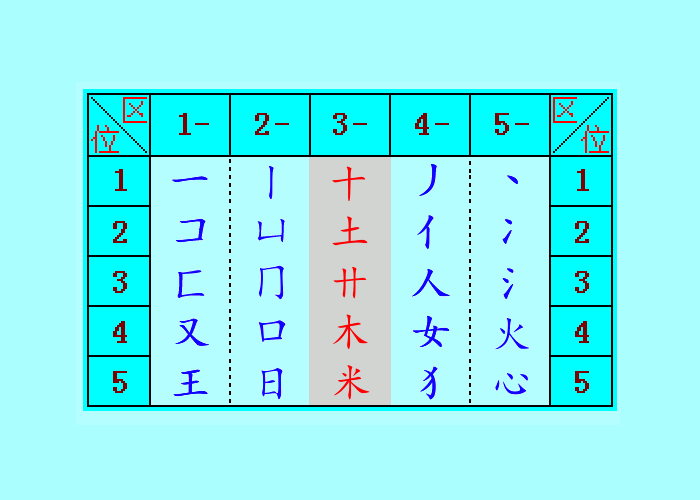
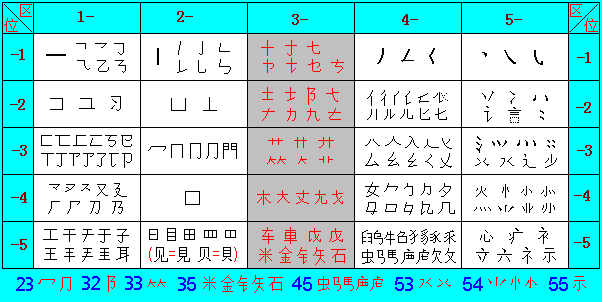
把字根表顺序用12345五个数字表示,就形成了25个数字码,数字化后的和码,不仅易学易记,还能在电脑的大键盘,数字小键盘上使用,也能在手机键盘上使用,从而实现了和码在不同的输入设备上完全的统一通用。
特别是在数字小键盘和手机上,和码输入软件有字根提示功能,只要输入字根的区号,软件就列示该区内的所有字根,并提示位号。有了这个逐码提示的功能,“和码字根表”25个码的记忆,就简化为“1横2竖3十4撇5捺”5个区号的记忆了。
以往的形码把汉字基本笔画分为“横竖撇点折”五类,因而也把字根表分为“横竖撇点折”五个区。 和码把汉字笔画分为“横竖撇点”四类,因而把字根表分的“横竖十撇点”五个区。汉字基本笔画的分类与字根表的分区还会有更好的方法吗?熟悉汉字字形结构的人,可能对此都不会抱有希望。
2、区内的排位方法: 和码把区内的笔画与字根,按其对字形与字义的限定性大小(由简到繁)的顺序分为5个位,这样的分区方法,有规律性,又有灵活性,使区内的字根位置易学易记,且编码对汉字的离散性好,重码少。
以往的形码区内排位方法有:
①按字根第二笔画的横,竖,撇,点(捺),折顺序排布。编码对汉字的离散性差,重码率大。如第一笔画是横,第二笔画是竖的字根有:‘扌土艹木’,第一笔画是竖,第二笔画是横折的字根有:‘冂口日目见’等,这些码上就集中了太多的汉字。
②、按部件的笔划数排序。编码对汉字的分散性差,重码率大。如:‘扌土艹大’在一个码上,‘亻人儿’在同一个码上,这些码上集中了太多的汉字。
字根在区内的排布方式,还有更好的吗?把上图表中的五列字根,打乱来,重新找个办法排排看。
笔画与字根按“横竖十撇捺”分区,区内按限定性由小到大的顺序分位,是和码汉字字形技术独有的创新,是最好最终的分区分位方法。
以往的25个码的汉字形码的单字取码方法都是:先把单字拆分成部件,后按“前三末一”取码,即按照字的书写笔画顺序取前三个部件码,第四个部件码取在字的最后位置。因前三码要依次取掉顺序书写的各个笔画,使部件(字根)集要包括汉字被拆开后的各个部分,这就使得部件(字根)多,形状多,难记。
和码对单字的取码方法是,先把单字按字义与字结构分块,后“以字块为单位,依书写顺序,核心字根优先”的原则,提取三个主码。最后在剩余部分取一个最大值码作为辅码,主码加辅码组成单字的全码。
和码的取码方法,是在字的几个(书写顺序的)不连续点,提取字根(或核心形义字根)。这种方法使得字根集不需要包括组成汉字的所有字根,因此和码字根表中笔画与字根少。和码的编码,能最大限度地包含了汉字最大的字义与字形信息。
25个码的汉字形码方案的单字取码方法,迄今为止只有两种,即“前三末一”与“以字块为单位,依书写顺序,核心字根优先”的原则,提取三个主码,再加上剩余部分取最大值码,后者为和码所独有。拿几个复杂的汉字,如‘壤魔蠢赚秉馨舆凹’来考虑一下,单字取码方法能有几种呢?
大家都知道汉字的笔画数有多有少,相差很大,英文字的字母个数也有多有少,汉字编码的个数,是否也应该随单字的笔画数的多少而变化呢?
我从以下三点来回答这个问题:
1、汉字字形编码是应该用单笔画码编码,还是用字根码编码;
2、用字根码编码,是否要限制码个数,多少个码最好;
3、和码单字编码采用三个主码加一个辅码方案的理由。
回答问题1: 如果采用单笔画,并且书写顺序编码,那么编码的长度就与字笔画数一致,但是这种编码方案,用于汉字输入与汉字排序检索,其效率很低,几乎没有使用价值。排除法可知,汉字编码只有采用字根码。
回答问题2: 字根‘一丨乚丿く丶’是一个笔画一个码,字根‘口王木目心’等是多个笔画一个码,因此采用字根对汉字编码,就没有码个数与单字笔画数应一致的关系。
采用字根对汉字编码,是否应该按照字的书写顺序,有多少个字根码,就取多少个字根码呢? 编码的实践说明:
①用字根对汉字编码,GB2312的6763个字的大部分字,在4个码以内就取完了所有笔画。读者可以用和码的字根表分析一下这个段落中的汉字,就知道了。
②4个码后,增加单字码长,对提高编码对汉字分辨率意义不大,特别是对提高常用3800(或5200)个汉字的分辨率没有作用。
③固定单字编码长度,给汉字输入带来方便,也方便软件处理。
在权衡利弊之后,发现增加单字的码长,没有实际意义。因此字根编码方案的着重点,是利用四个字根码,充分地提取汉字的字形字义信息,提高编码对汉字的分辨率。
回答问题3: 和码进一步分析单字各个码所含信息的内容与重要性的不同,以及在汉字输入过程中所起的作用的不同,把单字的四个码中的前三个码作为三个主码(主要码),第四码为与辅码(辅助码)。原因是:
A、绝大多数汉字,特别是常用汉字在输入的过程中,只用到前三码。
GB2312的6763个汉字中,和码有25个常用字只用到第一码;有25+629=654个单字,只用到前二码;有25+629+4458=5112个汉字只用到前三个码。也就是说,在输入这些单字时,前三码是有用的,第四码无用的,富余的。
词组的编码一般只用到单字的第一第二码,由此可知汉字输入过程中,第四码的重要性远不及前三码。
B、从码个数、码位个数与常用汉字的个数来分析。1个码有25个码位;2个码有25×25+25=650个码位;3个码有25×25×25+25×25+25=16275个码位。3个码的码位个数比国标GB2312中汉字个数6763多很多,比常用3800(或5200)个字多得更多。
由此可知,汉字编码方案,每个单字两个码是不够的,三个码在码位的数目上是有很多富余的。因此编码方案应尽可能地用3个码编出国标GB2312的6763个汉字,也应使前三码最大限度地包含汉字的字义、字形、与书写顺序信息。
C、第四码是起辅助作为的,用于分辨3个主码后仍存在的重码字(多为非常用字),包含单字主码取完后,剩余部分的字根信息,辅码不含书写顺序的信息。
汉字中许多字根是在字形或字义上是同源的,如:日→白(丿日);目→自(丿目);木→禾(丿木);厂→广(丶厂);冂→门(丶冂);王→主(丶王)、木→耒(一一木)、火→灭(一火)等等。
在核心形义字根前加上单笔画而形成的字根叫衍生字根。
和码字形技术引入核心形义字根及其衍生字根字根的概念,进一步简化了字根表。单字分块取码时,核心字根优先取码,使单字编码更多地提取主要形义信息。
在其它的汉字形码中,没有衍生现象的概念,同源字根(日→白;目→自;木→禾;厂→广;冂→门;王→主、木→耒)都被分开排布在不同的码上。
衍生字根是汉字字形的一个重要概念,是和码字形技术首次提出并应用的。
在第三节中,分析了在理想的编码情况下,25个码的编码方案的输入速度,也就是(理想的)极限速度。同时也说明了和码25个数字码的汉字编码统计数据,与理想的25个码的编码方案十分的接近。这也就说明了:和码编码方案的输入速度,已接近(25个码)的汉字输入速度的极限。
和码与其它汉字形码输入法速度的具体比较如下。
1、大键盘上的速度
输入法速度快慢的比较,其实非常简单,即看简码个数,简码多,那么输入的速度就快。
在字符集一定的条件下,完成这个字符集的单字输入(不使用词组),如击键数越少,这个输入法就越快(高效)。怎样做到更少的击键次数呢,这就看这个输入法一二三级简码数量是不是更多。只有简码数多,你打这个字符集的击键数才会更少,从而输入速度更快。因此,简码个数是决定输入法是否快速的关键性指标。下表是和码与五笔字型和大手笔两种输入法的比较:
| 名 称 | 一级简码 | 二级简码 | 三码字 |
| 和 码 | 25 | 617 | 4434 |
| 五笔字型 | 25 | 599 | 4397 |
| 大手笔 | 28 | 768 | 5339 |
注:此表使用了“大手笔输入法”网站上的五笔字型与大手笔的资料,其一、二、三级简码字有些重复,如‘不’同时出现在五笔字型的一二三级简码字中,‘话会好’同时出现在大手笔的二三级简码字中。和码的一、二、三级简码字是不互相重复的。
和码与五笔字型都是25个码的输入法,因此一码字都是25个,二码字和码比五笔多(617-599=)18个(至少),三码字比五笔多(4434-4397=)37个(至少)。因此和码比五笔字型的输入速度要快些。
大手笔输入法采用了28个码(在大键盘上使用了非字母符号),一码字,二码字,三码字都比和码多一些,由于常用汉字个数为有限的3800(或5200),根据上述第三项的分析,大手笔输入法的输入速度比和码不会有明显的提高(3%以内)。
《和码》、《五笔字型》、《大手笔》在输入速度上个差别很小,但《和码》字根表的易学易记性,以及电脑大键盘,数字小键盘与手机上的统一通用性,却是《五笔字型》和《大手笔》所不具有的。
2、手机或小键盘上的速度
A、25个数字码比10个数字码,对汉字的离散度大了许多,从理论上来看,一个码的离散度大25/10=2.5倍,2个码的离散度就大2.5×2.5=6.25倍,3个码15.625倍。实际情况是,因为汉字部件分到25个码上,比分到十个码上,分得具体细致得多,离散度相差的实际倍数,比理论值还高。
B、用25个码对于GB2312的6763个汉字编码,每个汉字取3个码,重码率情况比用10个码编码,每个汉字取6个码要低很多很多。
C、和码25个数字码对词组的容量与编码的离散性,是10个数字码的词组所无法比拟的。
因此25个数字码的和码在大键盘上的诸多优点(如:离散度高,取码次数少,重码率低),在小键盘上同样具有。且在小数字键盘上,每输入一个数字,都有常用字被选在待上屏位置,从而使输入第一个数字到第六个数字,能把GB2312的6763个汉字中的98%的常用汉字放到待上屏位置(即无需选字)。输入词组时才需要输入第七第八个数字码。
通过汉字集与汉字字形诸要素限定性的分析,以及形码方案的码个数,编码符号,字根表的分区分位方法,单字取码方法等,4个要素的限定性与各种选择性的分析,可以看出和码方案在每个要素上都采用了最好的办法,并且是最终的办法,因此和码是最好最终的汉字形码。
![]()
![]()